

AI coding agents can build a working app overnight. They can also quietly break what they’ve already built, and until now, no one has measured how often they do. TestSprite, the Seattle-based AI testing and verification platform, is dealing with both halves of that equation. It recently open-sourced the TestSprite CLI, a free tool that lets an AI coding agent check its own work before it calls a task done, and released first-of-their-kind data from its public CoderCup competition showing that even the strongest agents regress on a meaningful share of their own code.
The release targets a problem that has grown in lockstep with the agents themselves. Roughly 90% of web developers now use AI to generate code, according to Google Cloud’s DORA research. The leading agents now run unattended for hours and often overnight. Speed turns out to be the easy part. An agent will report a feature as finished when it has shipped a page that won’t load or will write a function that runs cleanly while quietly breaking something elsewhere. As TestSprite frames it, the bottleneck of AI-native development has moved from writing code to verifying it.
Most tools for checking code, from IDE plugins to dashboards, assume a developer sitting at a screen. An agent running overnight isn’t at one. It lives inside the terminal. So TestSprite built the CLI to live there too, as a command that the agent runs on its own with no human in the loop. The agent describes a behavior, and TestSprite runs it against the live app the way a real user would. When something fails, it returns a single bundle: the failing step, screenshots, a likely root cause, and a suggested fix. The agent reads it, fixes the code, and runs again. Every passing test is kept, so coverage grows alongside the build and catches the regressions that agents rarely think to look for.
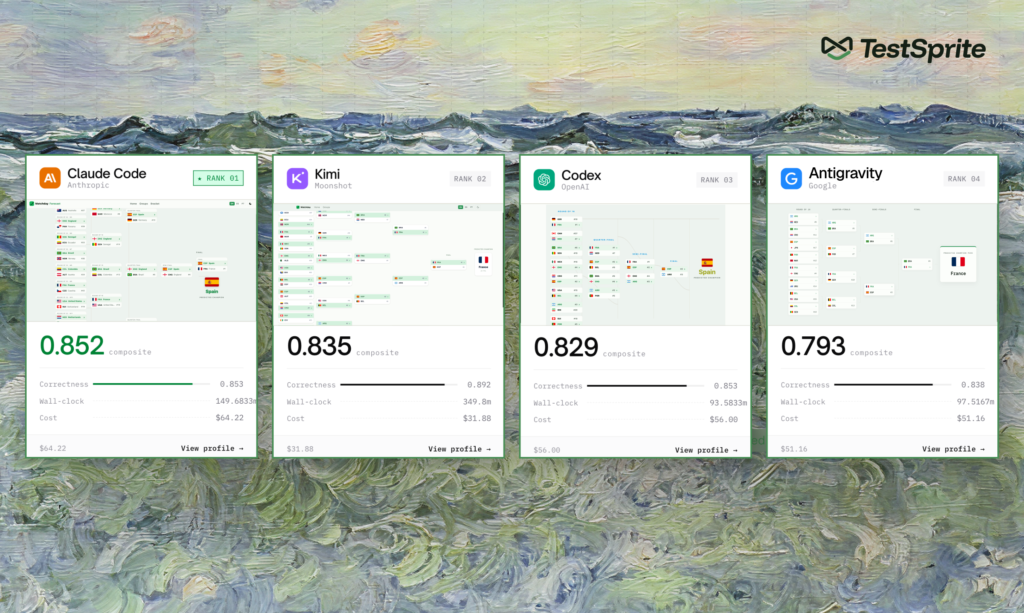
To prove the approach at scale, TestSprite paired the launch with CoderCup, a public competition at codercup.ai tied to this summer’s global soccer tournament. Frontier agents, including Anthropic’s Claude Code, OpenAI Codex, and Google Antigravity, each build the same ten-phase application under identical rules while TestSprite referees. Running verification across that field revealed numbers the industry has never systematically tracked. This included what an agent gets right on the first try, what it fixes after a failure is flagged, what it never gets right, and what it breaks along the way.
Two findings stand out. Agents can self-evolve once they have something to verify against. One agent began a phase with zero target features working and finished after 10 rounds of reading TestSprite’s feedback and fixing what it had broken, with roughly 80% of those features passing on the same underlying model. And regression is everywhere. The strongest run TestSprite measured still broke about 12% of its previously passing features in a single run, whereas weaker runs approached 25%. That is the single biggest reason a developer still has to babysit a supposedly autonomous agent.
-
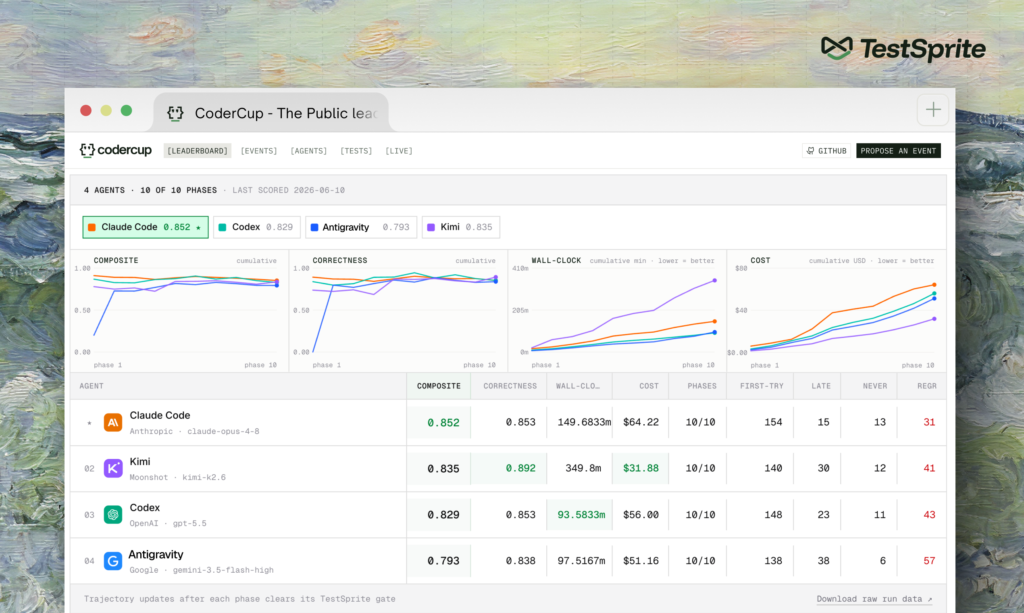
The full CoderCup leaderboard: composite score, correctness, time, cost, and regressions for each agent across ten build phases.
The data points to a counterintuitive conclusion for teams weighing which model to buy. In CoderCup, smaller and cheaper models reached the same feature-completeness as frontier ones after a dozen or more verification rounds, at a fraction of the total time and cost. The heavy lifting, TestSprite argues, comes from the verifier more than from raw model strength.
TestSprite released the CLI under the Apache 2.0 license so the developer community can extend it and wire verification into any agent workflow. “We open sourced the CLI because developers love it, and we want people around the world to be able to contribute,” said Yunhao Jiao, founder and CEO of TestSprite. “Verification is too foundational to the AI-native era to live behind a single vendor’s walls. The faster the community can shape this layer, the faster autonomous coding becomes something every team can ship on.”
The TestSprite CLI is available today and installs with a single command (npm install -g @testsprite/cli, on Node.js 20 or higher). It works with Claude Code, OpenAI Codex, and Google Antigravity. TestSprite, which says it supports more than 100,000 development and QA teams, has published CoderCup’s full task spec, scoring rubric, per-phase results, and repository at codercup.ai, so anyone can clone the project and re-run a phase to check the work. For a category racing toward agents that code on their own, the company’s bet is that the winners will be the ones who can prove what those agents built.






